hpurmann
Moving commits to another branch
Let’s say you made a few commits and then realized that you did them to the wrong branch. Because git is awesome, it’s really easy to change the branch you committed to.
Let’s learn why!
Commits
Every commit stores the SHA-1 hash of its parent commit(s). Think of it as a directed acyclic graph with each node pointing to its parent(s).

Branches
A branch is just a pointer to a commit. Git only stores a single file with the filename being the name of the branch. Inside, there is only the SHA-1 of the top-most commit.

Or to quote the great book Git Internals:
Creating a branch is nothing more than just writing 40 characters to a file.
Go for it and have a look in the .git directory of some git repository.
$ cd .git
$ ls
COMMIT_EDITMSG config hooks info objects
HEAD description index logs refs
$ cd refs/heads
$ ls
masterThe folder .git/refs/heads stores the branch reference files.
$ cat master
eb5c3831d6ebca824857d30cea70948201529adaLet’s say you are on the master branch and create another branch named dev.
$ git branch dev
$ cat dev
eb5c3831d6ebca824857d30cea70948201529adaThe new branch dev is pointing to the same commit as master. If we draw that, it would look like this:
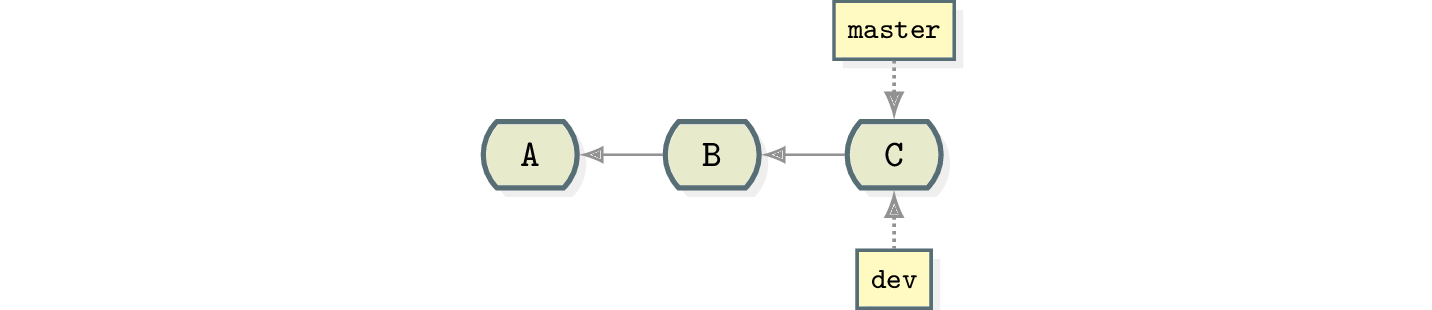
Back to the problem …
With the knowledge of commits and branches you can probably come up with a solution yourself.
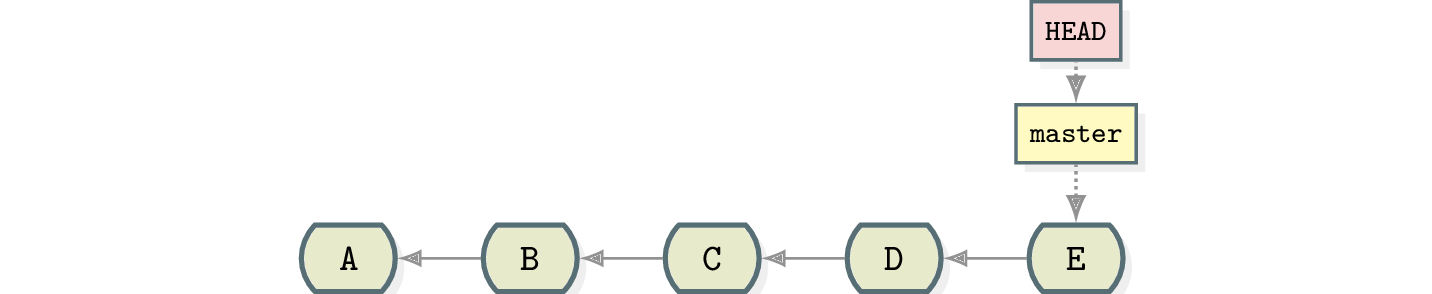
At this point you noticed that you want commits D and E on a new branch called feature1.
$ git branch feature1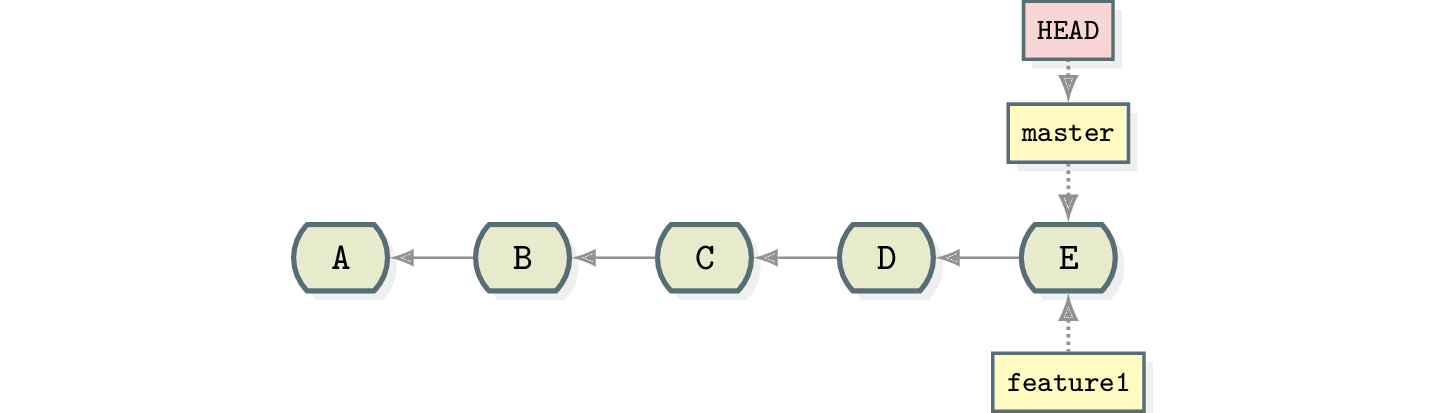
To “remove” the commits from the master branch, you simply move the branch pointer two commits back. Please note the two carets (^) behind HEAD.
$ git reset --hard HEAD^^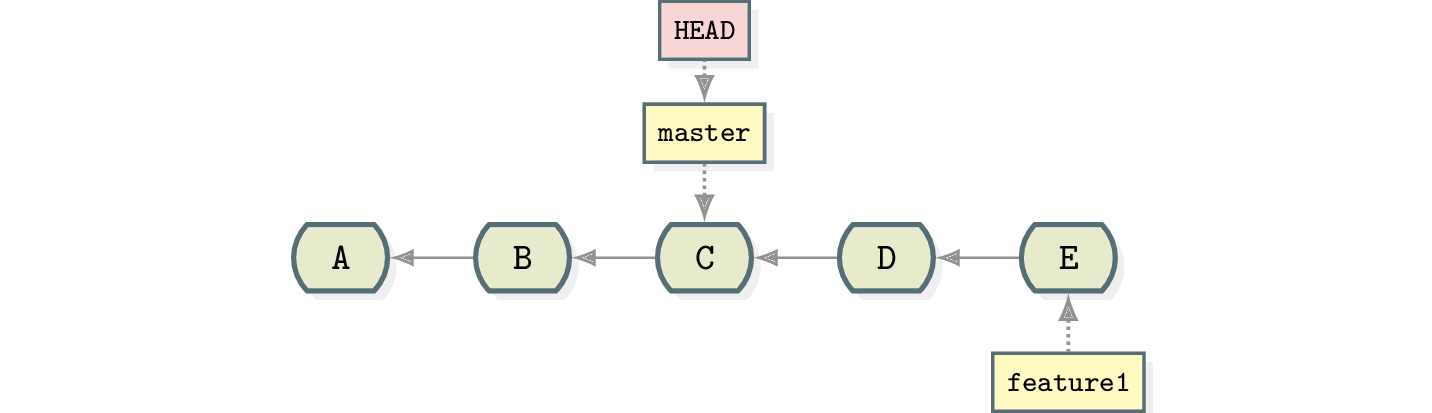
Because commits are just referencing their parents, D and E are now unreachable from master. Now you can just switch to your new branch and keep working on it.
$ git checkout feature1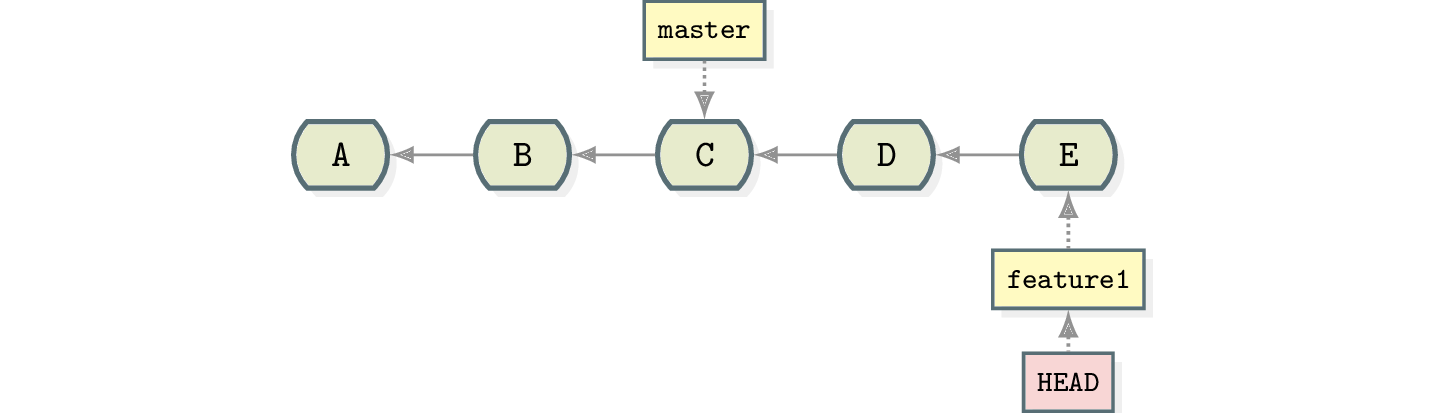
I hope you agree with me that this is really easy once you understood what these commands do internally. For further reading, I highly recommend reading the Think-like-a-git website and the mentioned Git Internals book by Peepcode.